Pubblications
2025
- ICCV
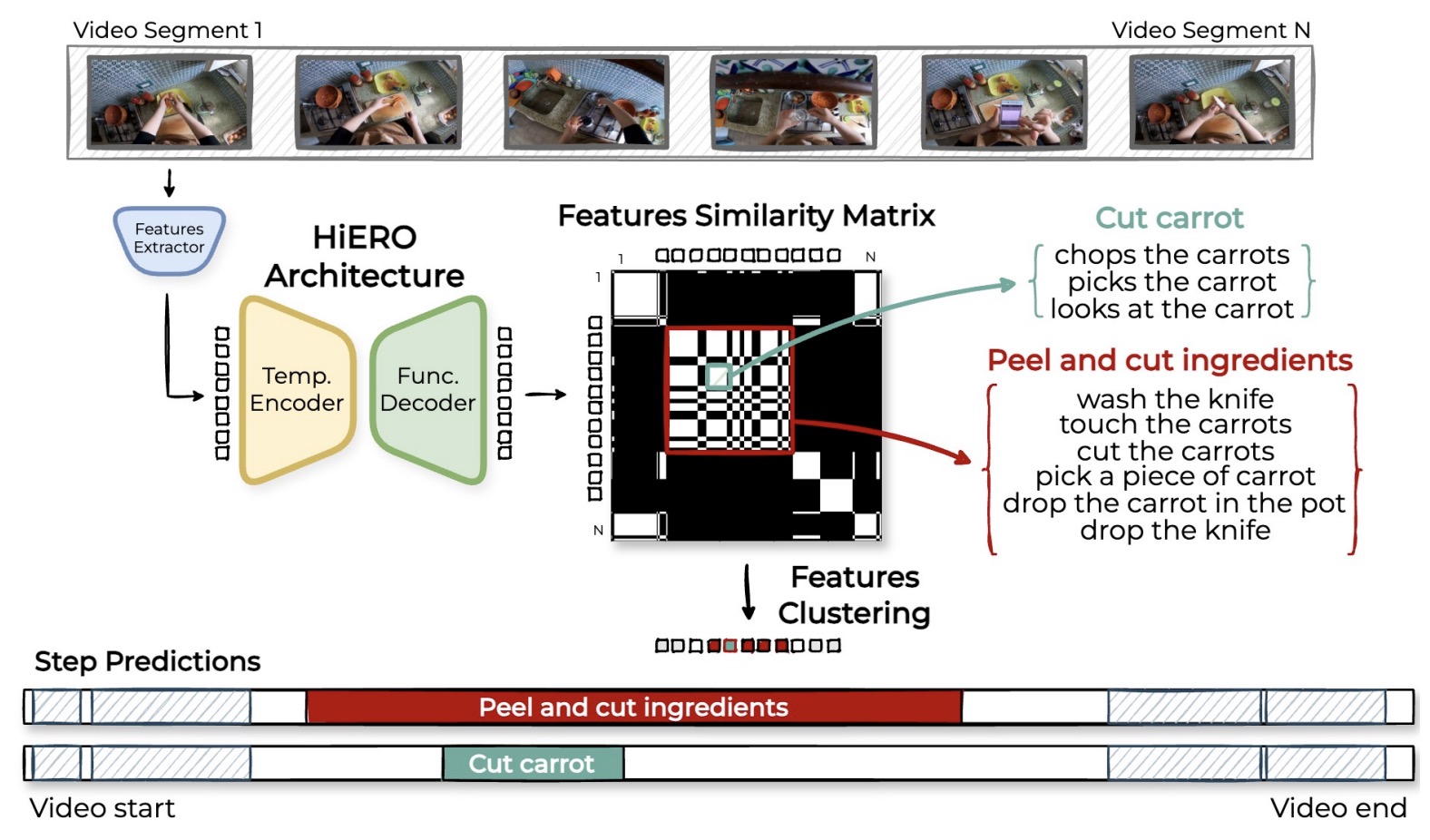 HiERO: understanding the hierarchy of human behavior enhances reasoning on egocentric videosSimone Alberto Peirone, Francesca Pistilli, and Giuseppe AvertaarXiv preprint arXiv:2505.12911, 2025
HiERO: understanding the hierarchy of human behavior enhances reasoning on egocentric videosSimone Alberto Peirone, Francesca Pistilli, and Giuseppe AvertaarXiv preprint arXiv:2505.12911, 2025Human activities are particularly complex and variable, and this makes challenging for deep learning models to reason about them. However, we note that such variability does have an underlying structure, composed of a hierarchy of patterns of related actions. We argue that such structure can emerge naturally from unscripted videos of human activities, and can be leveraged to better reason about their content. We present HiERO, a weakly-supervised method to enrich video segments features with the corresponding hierarchical activity threads. By aligning video clips with their narrated descriptions, HiERO infers contextual, semantic and temporal reasoning with an hierarchical architecture. We prove the potential of our enriched features with multiple video-text alignment benchmarks (EgoMCQ, EgoNLQ) with minimal additional training, and in zero-shot for procedure learning tasks (EgoProceL and Ego4D Goal-Step). Notably, HiERO achieves state-of-the-art performance in all the benchmarks, and for procedure learning tasks it outperforms fully-supervised methods by a large margin (+12.5% F1 on EgoProceL) in zero shot. Our results prove the relevance of using knowledge of the hierarchy of human activities for multiple reasoning tasks in egocentric vision.
@article{peirone2025hiero, title = {HiERO: understanding the hierarchy of human behavior enhances reasoning on egocentric videos}, author = {Peirone, Simone Alberto and Pistilli, Francesca and Averta, Giuseppe}, journal = {arXiv preprint arXiv:2505.12911}, year = {2025}, } - arXiv
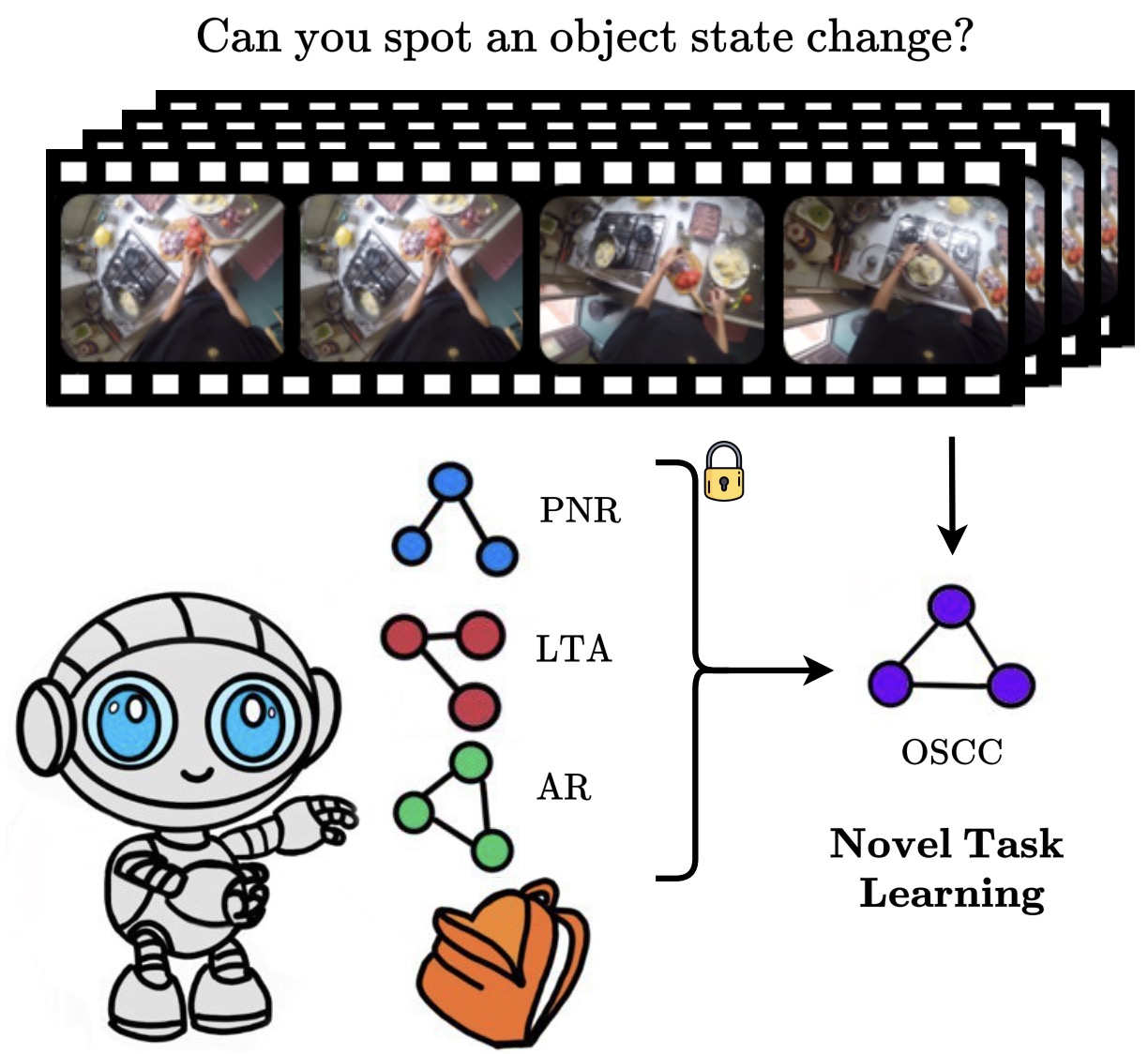
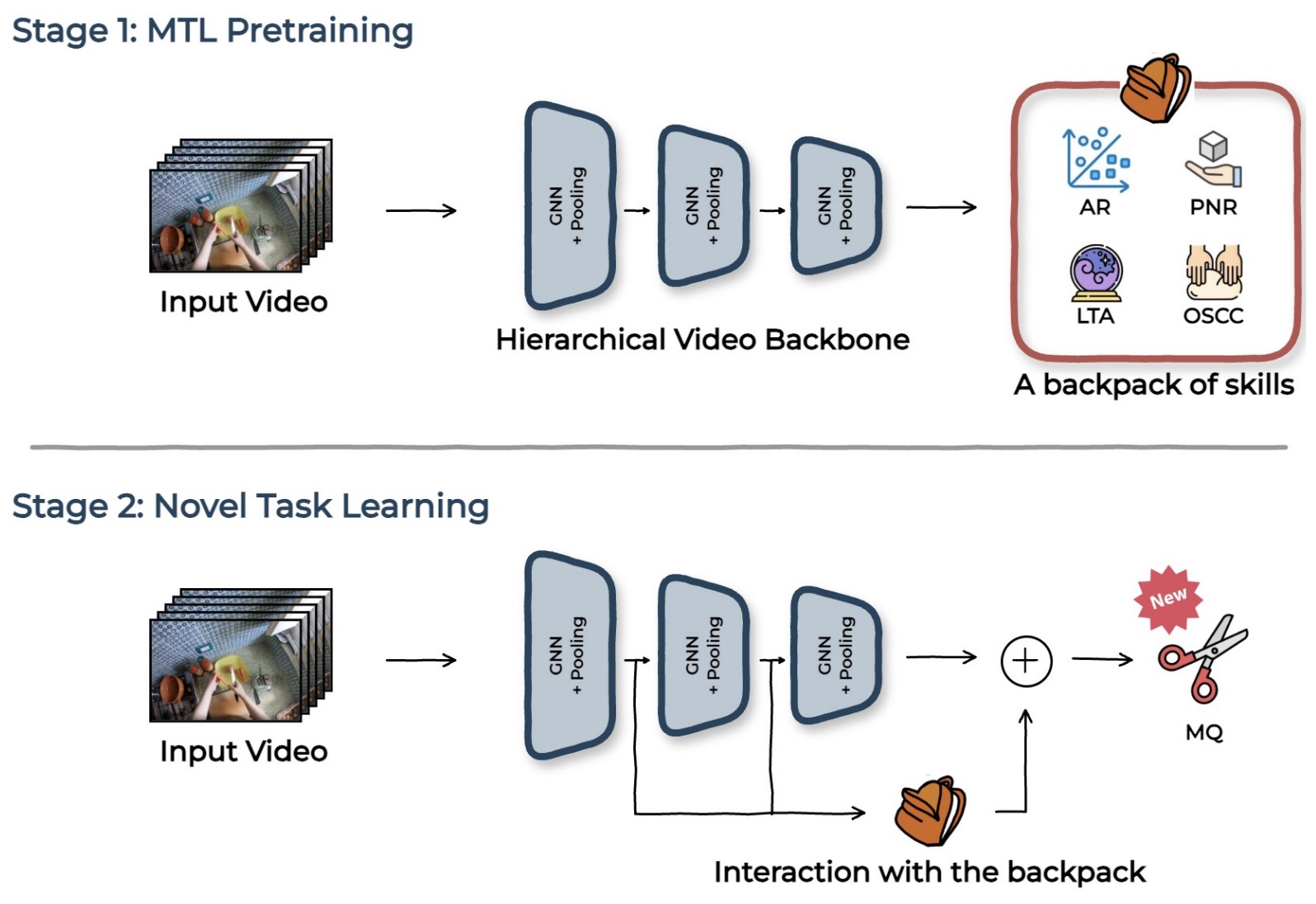 Hier-EgoPack: Hierarchical Egocentric Video Understanding with Diverse Task PerspectivesSimone Alberto Peirone, Francesca Pistilli, Antonio Alliegro, Tatiana Tommasi, and Giuseppe AvertaarXiv preprint arXiv:2502.02487, 2025
Hier-EgoPack: Hierarchical Egocentric Video Understanding with Diverse Task PerspectivesSimone Alberto Peirone, Francesca Pistilli, Antonio Alliegro, Tatiana Tommasi, and Giuseppe AvertaarXiv preprint arXiv:2502.02487, 2025Our comprehension of video streams depicting human activities is naturally multifaceted: in just a few moments, we can grasp what is happening, identify the relevance and interactions of objects in the scene, and forecast what will happen soon, everything all at once. To endow autonomous systems with such a holistic perception, learning how to correlate concepts, abstract knowledge across diverse tasks, and leverage tasks synergies when learning novel skills is essential. A significant step in this direction is EgoPack, a unified framework for understanding human activities across diverse tasks with minimal overhead. EgoPack promotes information sharing and collaboration among downstream tasks, essential for efficiently learning new skills. In this paper, we introduce Hier-EgoPack, which advances EgoPack by enabling reasoning also across diverse temporal granularities, which expands its applicability to a broader range of downstream tasks. To achieve this, we propose a novel hierarchical architecture for temporal reasoning equipped with a GNN layer specifically designed to tackle the challenges of multi-granularity reasoning effectively. We evaluate our approach on multiple Ego4d benchmarks involving both clip-level and frame-level reasoning, demonstrating how our hierarchical unified architecture effectively solves these diverse tasks simultaneously.
@article{peirone2025hier, title = {Hier-EgoPack: Hierarchical Egocentric Video Understanding with Diverse Task Perspectives}, author = {Peirone, Simone Alberto and Pistilli, Francesca and Alliegro, Antonio and Tommasi, Tatiana and Averta, Giuseppe}, journal = {arXiv preprint arXiv:2502.02487}, year = {2025}, } - PRL
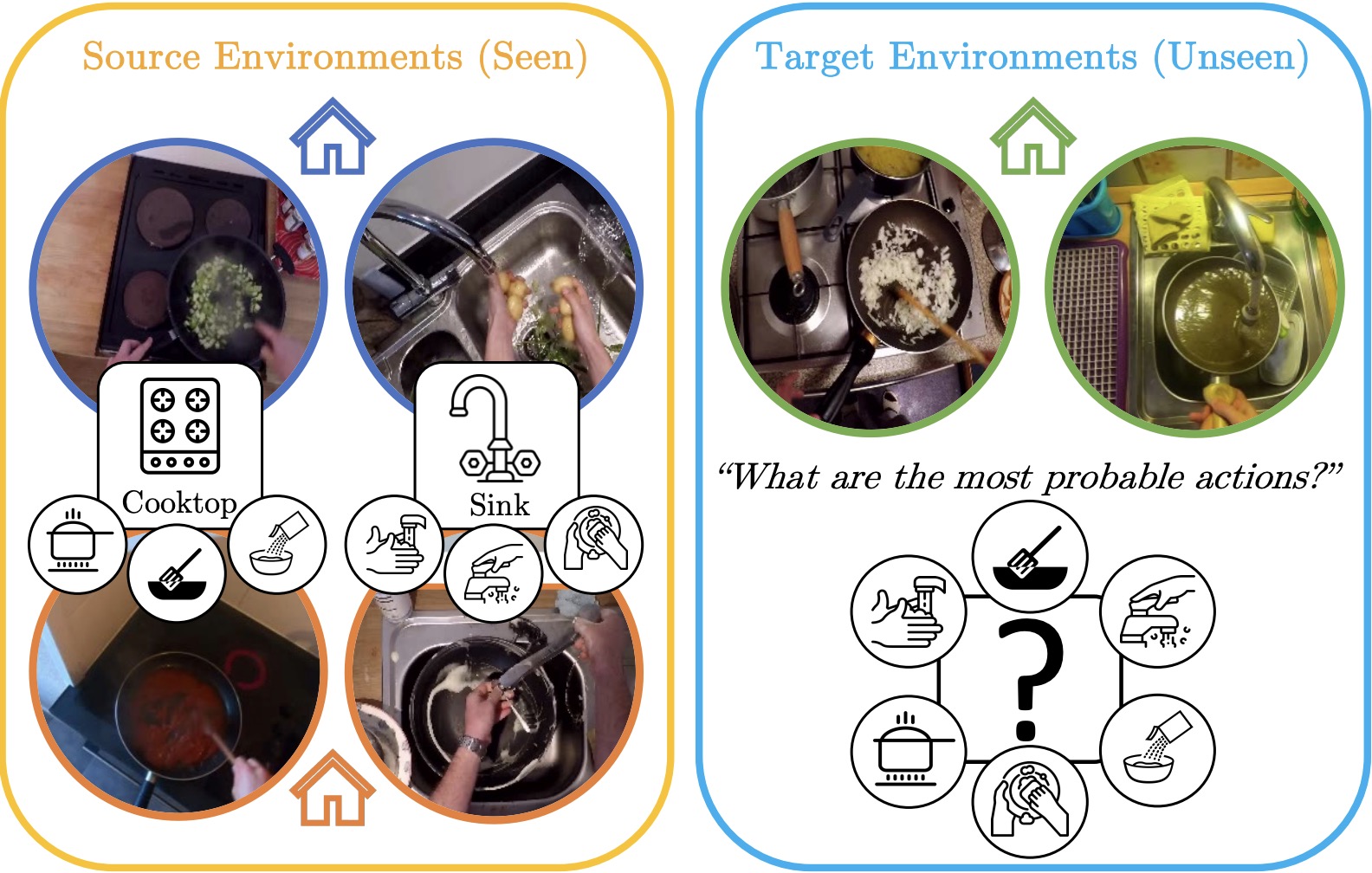 Egocentric zone-aware action recognition across environmentsSimone Alberto Peirone, Gabriele Goletto, Mirco Planamente, Andrea Bottino, Barbara Caputo, and Giuseppe AvertaPattern Recognition Letters, 2025
Egocentric zone-aware action recognition across environmentsSimone Alberto Peirone, Gabriele Goletto, Mirco Planamente, Andrea Bottino, Barbara Caputo, and Giuseppe AvertaPattern Recognition Letters, 2025Human activities exhibit a strong correlation between actions and the places where these are performed, such as washing something at a sink. More specifically, in daily living environments we may identify particular locations, hereinafter named activity-centric zones, which may afford a set of homogeneous actions. Their knowledge can serve as a prior to favor vision models to recognize human activities. However, the appearance of these zones is scene-specific, limiting the transferability of this prior information to unfamiliar areas and domains. This problem is particularly relevant in egocentric vision, where the environment takes up most of the image, making it even more difficult to separate the action from the context. In this paper, we discuss the importance of decoupling the domain-specific appearance of activity-centric zones from their universal, domain-agnostic representations, and show how the latter can improve the cross-domain transferability of Egocentric Action Recognition (EAR) models. We validate our solution on the EPIC-Kitchens-100 and Argo1M datasets.
@article{peirone2025egocentric, title = {Egocentric zone-aware action recognition across environments}, author = {Peirone, Simone Alberto and Goletto, Gabriele and Planamente, Mirco and Bottino, Andrea and Caputo, Barbara and Averta, Giuseppe}, journal = {Pattern Recognition Letters}, volume = {188}, pages = {140--147}, year = {2025}, publisher = {Elsevier}, }
2024
- CVPR
 A backpack full of skills: Egocentric video understanding with diverse task perspectivesSimone Alberto Peirone, Francesca Pistilli, Antonio Alliegro, and Giuseppe AvertaIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
A backpack full of skills: Egocentric video understanding with diverse task perspectivesSimone Alberto Peirone, Francesca Pistilli, Antonio Alliegro, and Giuseppe AvertaIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024Human comprehension of a video stream is naturally broad: in a few instants, we are able to understand what is happening, the relevance and relationship of objects, and forecast what will follow in the near future, everything all at once. We believe that - to effectively transfer such an holistic perception to intelligent machines - an important role is played by learning to correlate concepts and to abstract knowledge coming from different tasks, to synergistically exploit them when learning novel skills. To accomplish this, we seek for a unified approach to video understanding which combines shared temporal modelling of human actions with minimal overhead, to support multiple downstream tasks and enable cooperation when learning novel skills. We then propose EgoPack, a solution that creates a collection of task perspectives that can be carried across downstream tasks and used as a potential source of additional insights, as a backpack of skills that a robot can carry around and use when needed. We demonstrate the effectiveness and efficiency of our approach on four Ego4d benchmarks, outperforming current state-of-the-art methods.
@inproceedings{peirone2024backpack, title = {A backpack full of skills: Egocentric video understanding with diverse task perspectives}, author = {Peirone, Simone Alberto and Pistilli, Francesca and Alliegro, Antonio and Averta, Giuseppe}, booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, pages = {18275--18285}, year = {2024}, } - IJCV
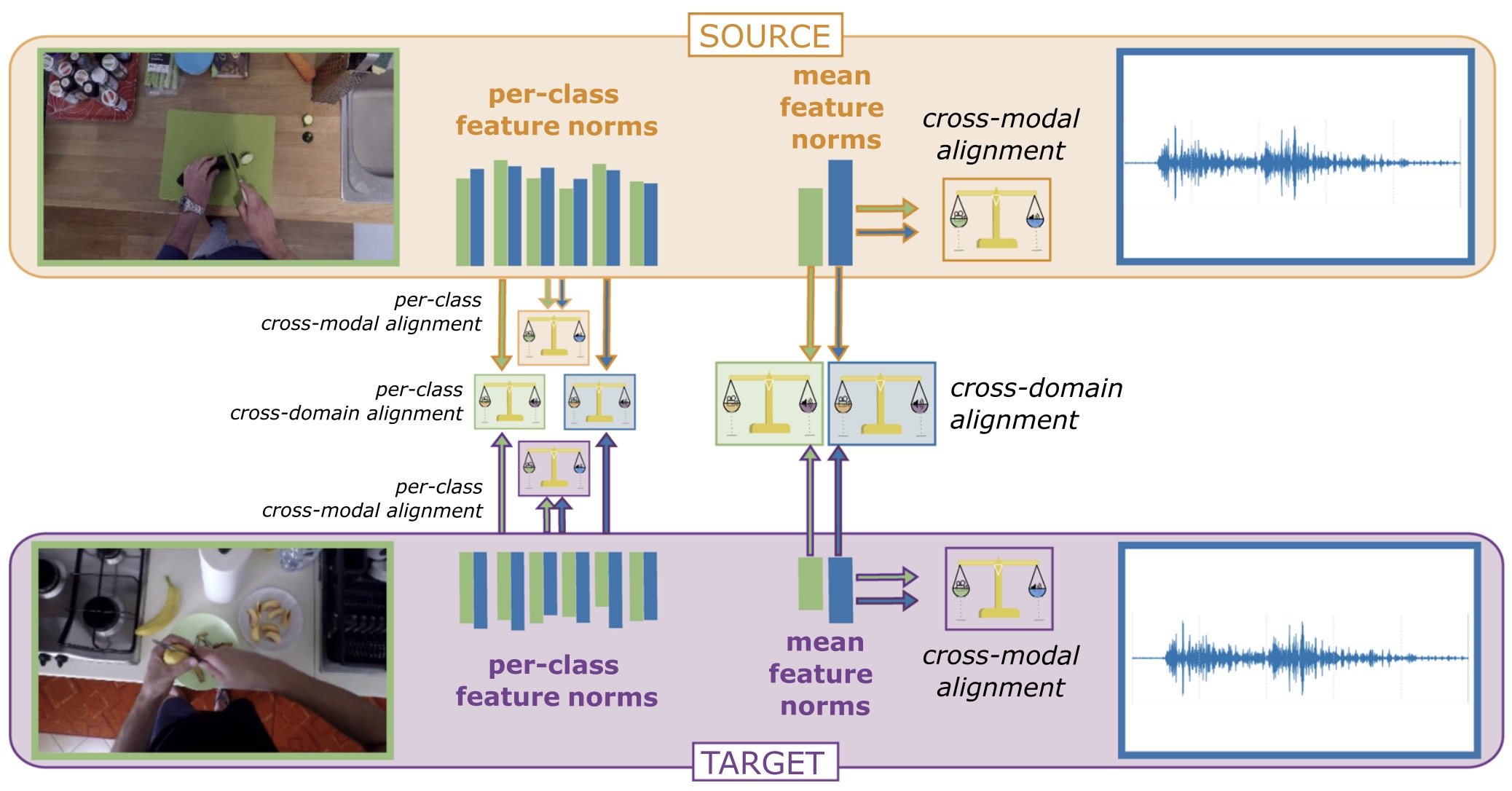 Relative norm alignment for tackling domain shift in deep multi-modal classificationMirco Planamente, Chiara Plizzari, Simone Alberto Peirone, Barbara Caputo, and Andrea BottinoInternational Journal of Computer Vision, 2024
Relative norm alignment for tackling domain shift in deep multi-modal classificationMirco Planamente, Chiara Plizzari, Simone Alberto Peirone, Barbara Caputo, and Andrea BottinoInternational Journal of Computer Vision, 2024Multi-modal learning has gained significant attention due to its ability to enhance machine learning algorithms. However, it brings challenges related to modality heterogeneity and domain shift. In this work, we address these challenges by proposing a new approach called Relative Norm Alignment (RNA) loss. RNA loss exploits the observation that variations in marginal distributions between modalities manifest as discrepancies in their mean feature norms, and rebalances feature norms across domains, modalities, and classes. This rebalancing improves the accuracy of models on test data from unseen ("target") distributions. In the context of Unsupervised Domain Adaptation (UDA), we use unlabeled target data to enhance feature transferability. We achieve this by combining RNA loss with an adversarial domain loss and an Information Maximization term that regularizes predictions on target data. We present a comprehensive analysis and ablation of our method for both Domain Generalization and UDA settings, testing our approach on different modalities for tasks such as first and third person action recognition, object recognition, and fatigue detection. Experimental results show that our approach achieves competitive or state-of-the-art performance on the proposed benchmarks, showing the versatility and effectiveness of our method in a wide range of applications.
@article{planamente2024relative, title = {Relative norm alignment for tackling domain shift in deep multi-modal classification}, author = {Planamente, Mirco and Plizzari, Chiara and Peirone, Simone Alberto and Caputo, Barbara and Bottino, Andrea}, journal = {International Journal of Computer Vision}, volume = {132}, number = {7}, pages = {2618--2638}, year = {2024}, publisher = {Springer}, }